- Published on
Pocket Universe - Bali
- Authors
- Name
- Justin Phu
- @jqphu
I found myself in Bali, Indonesia with one goal and one goal only - find an idea for my startup.
I had just finished a three month accelerator (HF0) in Miami where I tried a variety of ideas. Despite learning a lot, all of the ideas amounted to nothing. I had just left my job at Meta where I was newly promoted to a Staff Engineer (E6) to pursue this startup but we had no idea what we were doing. Nish (my co-founder) and I needed to decide what we were going to work on. We decided to shut ourselves away from the world by flying to Bali and focus entirely on the startup. This blog post is my account of how the three months went!
Jun 15th - Touchdown in Bali
Nish and I were excited to continue working in crypto but we watched enough YC videos to know that we needed to solve a real problem. No hypothetical use-case that would be realized in a year. A problem that the market would pull from us that only we could solve.
The plan was pretty simple. Spend the first 6 weeks learning and trying things. Then pick an idea and validate it in the next 6 weeks. I decided to start by doing Macro Engineering Fellowship (https://0xmacro.com/engineering-fellowship) and learning more about smart contracts. Nish went on a grand tour of crypto writing one pagers about DeFi, ZeroKnowledge Proofs, Stablecoins!
We had some ideas:
- Reputation system for DeFi for better loans
- Lending based on future income
- Transferring ETH safely without typos
However, none of them 10x. None of them felt real.
June 29th - Time to Code!
I finished the Macro Engineering Fellowship on the 29th of June. With that done and dusted, it was time to go explore with Nish so I started reading into DeFi papers and looking into DEXs. However, frankly I was bored. I like to build. I wanted to do something.
I was doom scrolling twitter looking at ETH NYC hackathon projects and ran across Safe Node. He was able to build an RPC node that blocked malicious transactions. I thought this was brilliant! Back in HF0, we knew scams were a huge problem in the crypto space but couldn't find effective solutions.
I dm'd Stanley (the winner of SafeNode) to chat about this idea. In the meantime, Nish and I explored how we could take this idea to the next level.
The first thing we thought was, this user experience was a bit cumbersome. Having to open up a new browser every time to confirm a transaction kind of sucks. Let's meet users where they are with a Chrome extension. The majority of users were using MetaMask so what if we could just display information there.
Nish begins to go validate that this is a real problem by searching through twitter of people saying they've been scammed. I begin playing with Chrome extensions and building out the first iteration.
After chatting to Stanley to see if he was planning on taking this project further it seemed like he wasn't. So we went ahead and said let's just try it out. Let's build something and if it amounts to nothing who cares. We set out to find 3-5 users that would be willing to try out our extension.
To my surprise Nish managed to find those users in a heartbeat. I guess this was a real problem because they were willing to try a random Chrome extension from an unknown person on twitter.

July 5th - The MVP
The idea of the MVP was fairly simple.
- Install a Chrome extension.
- Associate each Chrome extension with a unique identifier (e.g.
a13b80dd). - Craft a unique node url (
http://pocketuniverse.app/rpc/a13b80dd) for the user to put in MetaMask. - Now when MetaMask wants to send a request, they'd send it to us. We'd run that through Tenderly and analyze the output to see if there are any scams.
Tech Stack:
- Chrome extension
- AWS EC2 running an express server
- Tenderly to run simulations
By July 9th we had the MVP complete but there were a two issues. Installing the extension with the custom RPC node required a very convoluted process of going into the settings of MetaMask. Stanley warned me of this but we decided to proceed anyway.
Secondly, we couldn't trigger the Chrome extension to popup through our server. It requires the user to take an action. Remembering to click our extension would be behavior we would have to make them learn. That's always complicated.
Back to the drawing board. We needed to make this experience better.
July 9th - The MVP again!
After brainstorming some ideas we ended up going with a simple insight "why don't we just be the wallet". Instead of being an RPC node that MetaMask sends requests to, what if we pretend to be a wallet to capture the request first and never send it to MetaMask at all.
This has the benefit of never signing a malicious transaction as it will never get to your wallet. This means we will be able to solve both problems:
- The RPC node setup isn't needed anymore, just install the extension and you're good to go!
- We can trigger the popup since the event came from the webpage itself (user action).
At the same time, I was learning more about web technologies. Note, my background prior to this was operating systems. We didn't use EC2 instances, we were building the thing EC2 instances run on - a kernel!
I came across this AWS Lambda. Instead of running a full machine, I could just spin up AWS Lambdas whenever I needed. This was great this my application was entirely stateless.
Tech Stack:
- Chrome extension
AWS EC2 running an express serverAWS Lambda running a typescript function- Tenderly to run simulations
Not only did I re-write the extension entirely, I re-wrote the backend entirely too. Fun.
We finished the second MVP by July 12th and had it ready in the Chrome store by July 14th!
July 14th - SHIP SHIP SHIP
What we learnt from watching infinite YC videos was we needed to get our product in the hands of users as fast as possible. So we did that by finding anyone we could who had been scammed to see if this would help them. They've felt the pain before so we'd hope they'd be yearning for a solution.
We managed to ship to 6 customers in the first week. We were ecstatic. Someone, anyone was using something we built.
Here's a snippet from our notion.


Now as soon as we shipped, of course everything was broken. There were a million edge cases we didn't handle. We rolled out updates to production which were buggy.
We fixed these problems as they came along. That's the beauty of shipping - you find out everything that doesn't work.
July 19th - Bug Fix and Grow
The plan now was simple, get more users and make sure the product works.
Nish would find every scam he could on twitter, and let everyone know that he had a solution to this problem.
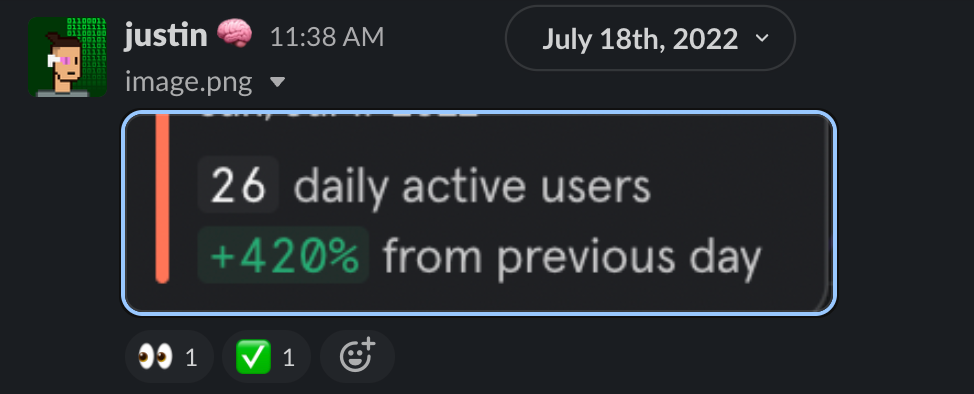
Slowly, but steadily we started getting more users.

Our Twitter started growing.

We started getting noticed.


With more users comes more problems.
- The extension doesn't work on certain websites
- The extension works too much - it is popping up twice!
- There's this weird mint where nothing happens
- The serverless functions are timing out
- We need to upgrade our Tenderly subscriptions
- We need to open source to help build trust
I was busy everyday just fixing whatever came in. I was so busy building that I didn't realize we were growing so quickly (this ended up being a recurring theme until the last few months). By July 31st we were at 1000 weekly active users! I was so happy to have 20 users, it was insane to have 1000.
The one problem that continued to plague us was our simulations kept timing out and they were slow. Our P99 was over 2 seconds.

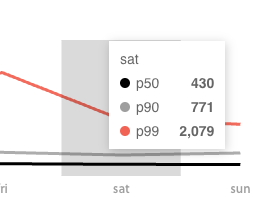
This was bad because a mint can be very contested and if we take too long people will uninstall us. Around this time as well, we also signed our first deal with a wallet to use our API. I didn't want us to lose that deal because our API was too slow. I asked myself the dangerous question "what if replace this service with something we do in-house".
All I really needed to do was run the EVM. We could optimize things since we didn't care about historical simulations and only wanted to run on the latest block. I had a lot of ideas on how we could make it really fast.
Now generally I would be very hesitant to bring more things in-house. Maintence overhead is insane especially this early on when we've barely cracked 1000 users. However, this part of the stack was critical to our business and the user experience so we decided to try it.
The plan was to still use a node like Alchemy for the blockchain data but run the simulation ourselves using our own EVM.
July 31st - Building the MVP Simulator
I decided to write the simulator in Rust.
Why?
Not quite because of safety. Not quite because of performance. Just because I wanted to and enjoyed the language. Being the only engineer on the team, whatever I was productive in mattered the most.
After a week we had a basic simulator running which could process transactions. It would use Alchemy and QuickNode to get the blockchain data.
I set up a stress test to measure the latency. I listened to every transaction in the mempool and replayed it with our custom simulator.
The results ended up as follows.
Alchemy
- median - 102ms
- P99 - 2025ms
QuickNode
- median - 13ms
- P99 - 262ms
Now what we really cared about was the P99 since a lot of eth transactions are basic transfer but our users were NFT degens. There was a gigantic disparity between QuickNode and Alchemy. Great, let's just use QuickNode I thought.
However, at the time QuickNode would occasionally crash with "block number not found". The reason is I would request the block number from one node which was up to date. Then I would request some data for that block number. However, I'd get routed to another node which wasn't up to date yet. This would cause the request to fail since the number wasn't found.
Correctness and stability was much more important that speed. However, Alchemy was not much better than just using Tenderly. Did I just waste my time?
August 4th - Do Everything Yourself
I thought to myself, the EVM is trivial - what's taking so long. The reason was we were getting all the data over the network.
If the EVM was on the same machine as the ETH Node itself it would be just as fast as reading from disc. There's no way running the EVM (which is incredibly simplistic) and reading from disc should be that slow.
So... why don't we just run our own node.
We started setting up an EC2 instance and I picked this new and upcoming node called Akula. The reason? It was written in Rust. At some point I wanted to have the simulator be part of the node itself so picking something in the same language as my simulator made sense.
Syncing the node took FOREVER so I asked the Akula team how to speed it up. They recommended I get a bare metal machine with a SSD and dedicated resources. It has a super fast SSD, it was cheaper and we had a consistent workload - what could go wrong.
Next thing I knew I had a Hertzner bare metal server running an eth node.
Once the node was synced I was too excited that I couldn't sleep. I had to get it working. At 7AM I finally got everything working and the numbers were amazing.

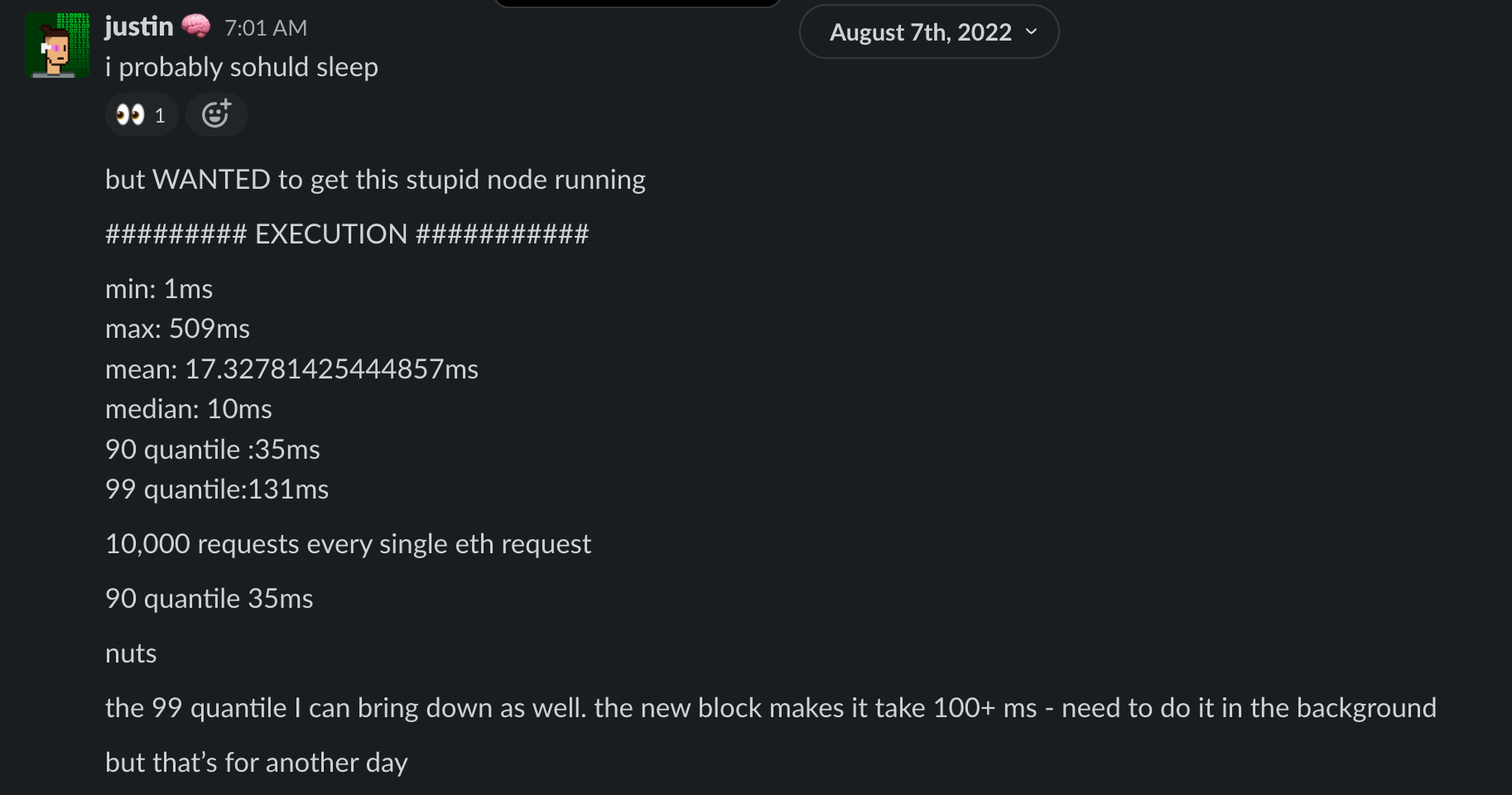
On that single machine, I was able to run EVERY SINGLE ETHEREUM TRANSACTION under 150ms. The machine barely broke a sweat.
August 7th - Productize
Things worked... but only in theory. There was no way this was ready to go out to our users.
I spent the next week working on bringing it up to speed ready for production. Setting up docker swarm for zero downtime deployments. Setting up monitoring with DataDog to see what's going on and set up basic alerts.
Before we were ready to ship, I decided to test it on production data. I updated our serverless to do a request to Tenderly and a request to our server.
It seemed fine for a day. I initially planned to double check that the tenderly results and our simulator results were the same. However, I thought maybe it's just easier to test in production. So I went ahead and shipped it.

Surprisingly - everything worked fine!


Now our simulations were < 150ms, fetching metadata would take >500ms and was our new bottleneck. As a quick fix, our metadata service was located in the US so we just moved our simulator to a datacenter in the US to shave some time there.
With some quick optimizations today our simulation latency P99 is < 50ms. Our overall P99 latency is ~700ms and P50 ~500ms. A majority of the time simply fetching data from other services. This was fast enough that the simulation time wasn't noticeable. I have plenty of ideas to make it even faster but that's for another day.
Tech Stack:
- Chrome extension
AWS Lambda running a typescript functionTenderly to run simulationsBare metal machine running some Rust code :P
August 18th - Failures
The benefit of owning the entire stack is I could control the end user experience. The downside of owning the entire stack was the errors! Instead of blaming another service, I only had myself to blame and boy did things go wrong fast.
On August 18th, the node just stopped syncing. This is what I get for using cutting edge technology.
Now I had no idea why the node wasn't syncing and I couldn't bring it back to stability. I could sync a new node, but that'd take 72 hours. I quickly patched it by pointing to alchemy but that spiked our simulation time to 2-3 seconds. I tried using QuickNode but we ran into the previous issue of it crashing.


The next 2 hours was me firefighting figuring out how to fix things. Talking to the Akula devs and running any command I could.

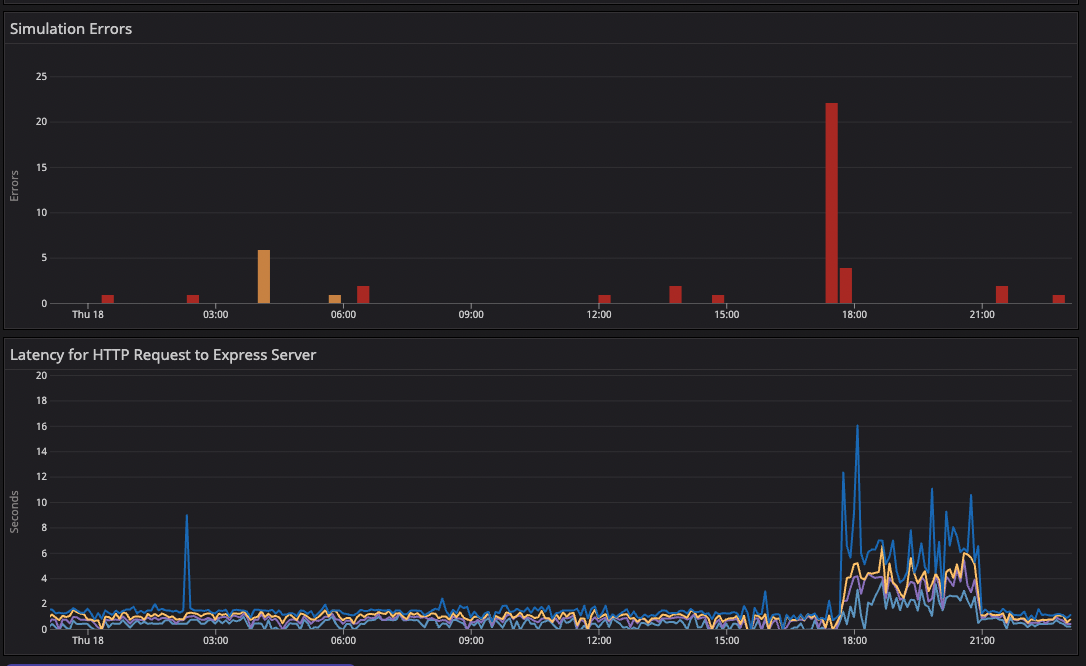
Eventually I fixed it and everything was back to normal!
We clearly weren't ready to handle disaster scenarios so I spent the rest of the week working on that. Adding an on-call so I'd get a phone call when things went wrong. Adding more monitoring for datadog so we can find issues. Adding a CloudFlare load balancer to automatically shift load to a backup server if issues were found.
Tech Stack:
- Chrome extension
- Bare metal machine running some Rust code
- DataDog
- BetterUptime
- Docker
- CloudFlare
Learnings
Before I knew it, it was time to head back to Australia.
I was too busy building infrastructure and product features that I didn't internalize that we had almost 5,000 users! That was insane.
We made so many mistakes in those three months. Technical mistakes, product mistakes and business mistakes. But there was one thing we did right which was make those mistakes quickly. We built, threw things away, built again.
I learnt it's important to own parts of the stack that are critical to your business. Even if there aren't many performance improvements, the understanding of what's going on is incredibly useful.
At the end of the day, I left Bali satisfied. I didn't just hit my goal of finding an idea but were helping thousands of people not lose their money every single day. Little did I know, this was just the start of the journey.